Flowcept Architecture¶
Overview¶
Flowcept follows established distributed design principles and is extensible to support multiple MQs as backends, multiple database models (e.g., Document, Relational, Graph), and LLM-based agents. This provides a flexible, loosely coupled framework that scales from small centralized workflows to large HPC workflows across the Edge–Cloud–HPC (ECH) continuum.
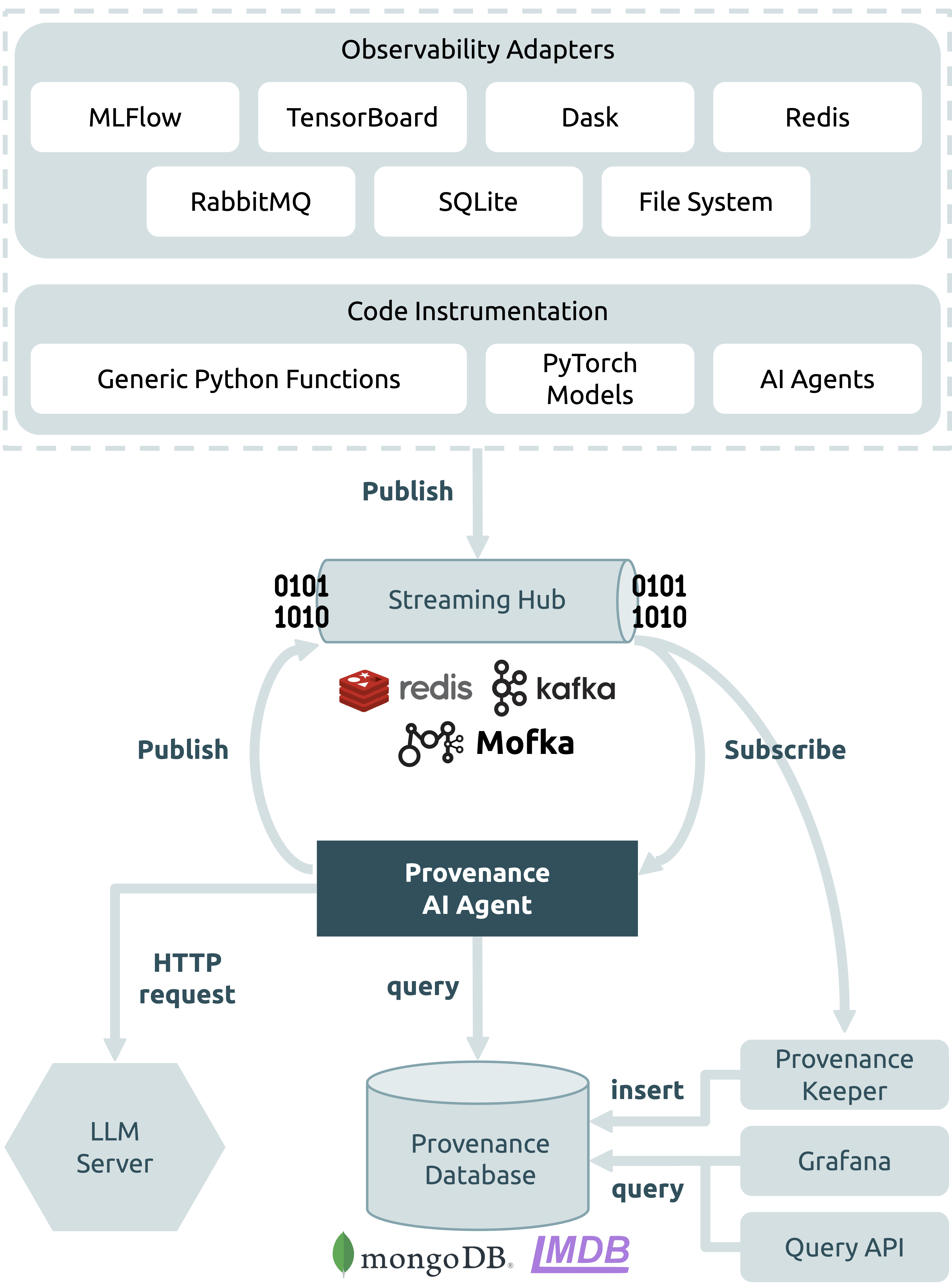
Capture Mechanisms¶
The architecture prioritizes interoperability and deployment flexibility through a modular, adapter-based design. Provenance capture happens via two complementary mechanisms:
Non-intrusive observability adapters Passively monitor dataflow from external services such as RabbitMQ, SQLite, MLflow, and file systems. These require no code changes and can capture provenance from workflows or engines that already use these services.
Direct code instrumentation Uses lightweight hooks (e.g., Python decorators) to capture fine-grained task metadata directly from code. This includes functions, script blocks, or specialized tools such as Dask tasks, PyTorch models, and MCP agents.
Together, these mechanisms offer flexible entry points to support heterogeneous workflows.
Streaming Hub and Buffering¶
To minimize interference with HPC applications, provenance messages are buffered in memory and streamed asynchronously to a publish–subscribe hub. Flowcept supports configurable flushing strategies and multiple broker backends:
Redis → low-latency messaging, minimal setup, default for most use cases.
RabbitMQ → AMQP-based broker, suitable for cloud and enterprise environments.
Kafka → high throughput for data-intensive workflows.
Mofka → RDMA-optimized transport, ideal for tightly coupled HPC networks.
Regardless of the broker, all provenance messages follow a common schema.
Provenance Keeper and Storage¶
One or more distributed Provenance Keeper services subscribe to the hub and convert messages into a unified schema based on a W3C PROV extension. They can store provenance into different backends, depending on performance and query needs:
MongoDB → efficient bulk writes and flexible aggregation queries.
LMDB → lightweight key–value store, optimized for high-frequency inserts.
Custom → Other storage mechanisms can be implemented by following Flowcept’s Base Consumer class. See here.
Access and Querying¶
Users can access provenance data through multiple interfaces:
Query API (language-agnostic, usable from Python or Jupyter)
Grafana dashboards for monitoring and visualization
Natural language queries through Flowcept’s LLM-powered agent (introduced in this work)
See more about querying.
Deployment Flexibility¶
Each component can be deployed independently across the ECH continuum. For lightweight use cases, a single broker may suffice. For federated or large-scale workflows, brokers can be composed into federated hubs tailored to specific reliability or performance requirements.